Basically,
an OODBMS is an object database that provides DBMS capabilities to objects
thathave been created using an object-oriented programming language (OOPL). The
basic principle is to add persistence to objects and to make objects
persistent.
Consequently
application programmers who use OODBMSs typically write programs in a native
OOPL such as Java, C++ or Smalltalk, and the language has some kind of
Persistent class, Database class, Database Interface, or Database API that
provides DBMS functionality as, effectively, an extension of the OOPL.
Object-oriented
DBMSs, however, go much beyond simply adding persistence to any one object-oriented
programming language. This is because, historically, many object-oriented DBMSs
were built to serve the market for computer-aided design/computer-aided manufacturing
(CAD/CAM) applications in which features like fast navigational access,
versions, and
long transactions are extremely important.
Object-oriented
DBMSs, therefore, support advanced object-oriented database applications with
features like support for persistent objects from more than one programming
language, distribution of data, advanced transaction models, versions, schema
evolution, and dynamic generation of new types.
Object data
modeling
An object
consists of three parts: structure (attribute, and relationship to other
objects like aggregation, and association), behavior (a set of operations) and
characteristic of types (generalization/serialization). An object is similar to
an entity in ER model; therefore we begin with an example to demonstrate the
structure and relationship.
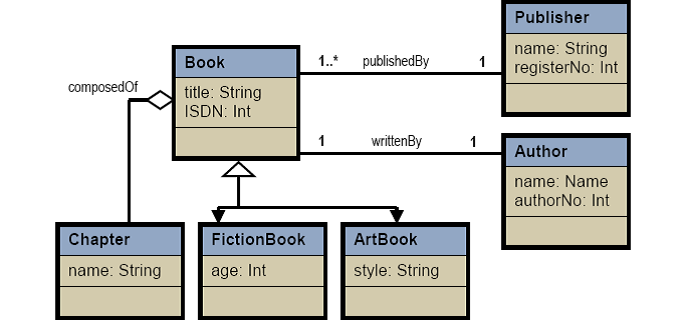

Attributes
are like the fields in a
relational model. However in the Book example we have,for attributes
publishedBy and writtenBy, complex types Publisher and Author,which are also
objects. Attributes with complex objects, in RDNS, are usually other
tableslinked by keys to the employee table.
Relationships: publish and writtenBy are associations
with I:N and 1:1 relationship; composed_of is an aggregation (a Book is
composed of chapters). The 1:N relationship is usually realized as attributes
through complex types and at the behavioral level. For example,

Generalization/Serialization
is the is_a relationship,
which is supported in OODB through class hierarchy. An ArtBook is a Book,
therefore the ArtBook class is a subclass of Book class. A subclass inherits
all the attribute and method of its superclass.

Message:
means by which objects
communicate, and it is a request from one object to another to execute one of
its methods. For example:
Publisher_object.insert
(”Rose”, 123,…) i.e. request to execute
the insert method on a Publisher object )
Method: defines the behavior of an object. Methods
can be used
. to change
state by modifying its attribute values . to query the value of selected
attributes The method that responds to the message example is the method insert
defied in the Publisher class.
The main
differences between relational database design and object oriented database
design include:
• Many-to-many
relationships must be removed before entities can
be translated into relations. Many-to-many
relationships can be implemented directly in an object-oriented database.
• Operations are
not represented in the relational data model.
Operations are one of the main components
in an object-oriented
database.
• In the
relational data model relationships are implemented by
primary and foreign keys. In the object
model objects communicate through their interfaces. The interface
describes the data (attributes) and operations (methods) that are visible to
other objects.


